
Если вы хоть раз нарисовали картинку и выложили в интернет, даже если она не стала популярной - скорее всего, эта картинка уже прожевана нейросетью.
В этом посте я собрала известные факты о моделях, на которых обучают нейросети и покажу вам какие именно картинки лежат в основе “работ” нейросеток.
Надо понимать, что не вся информация о моделях открыта и известна, но благодаря Stable Diffusion и ее открытой документации стало возможным исследовать хоть на чуть-чуть из каких же “открытых источников” тянутся все изображения.
Самый огромный датасет на сегодня LAION-5B - 5,85 миллиардов пар картинка-текст, который скармливают нейросеткам для обучения. Как нейросети работают я очень подробно рассказывала в другом посте, поэтому не буду еще раз на этом останавливаться. Именно на LAION-5B обучали Stable Diffusion, датасет открыт и дает возможность заглянуть внутрь. Правда, чтобы найти ссылку для входа, придется побыть детективом.
На сайте LAION создатели пишут:
Мы представляем LAION 5B, крупномасштабный набор данных для исследовательских целей, состоящий из 5,85 миллиардов пар изображение-текст, отфильтрованных с помощью CLIP. 2,3 миллиарда содержат английский язык, 2,2 миллиарда образцы из более чем 100 других языков и 1 миллиард образцы содержат тексты, которые не допускают присвоения определенного языка (например, имена). Кроме того, мы предоставляем несколько индексов ближайших соседей, улучшенный веб-интерфейс для исследования и создания подмножеств, а также оценки обнаружения водяных знаков и NSFW.
А еще отвечают на вопрос, зачем они вообще это создали:
Мотивация создания набора данных заключается в том, чтобы демократизировать исследования и эксперименты, связанные с обучением крупномасштабных мультимодальных моделей и обработкой некурируемых крупномасштабных наборов данных, сканируемых из общедоступного Интернета. Поэтому мы рекомендуем использовать набор данных в исследовательских целях. <…> Мы считаем, что открытое предоставление набора данных широкому исследованию и другим заинтересованным сообществам позволит провести прозрачное исследование преимуществ, связанных с обучением крупномасштабных моделей, а также подводных камней и опасностей, которые могут остаться незамеченными при работе с закрытыми большими наборами данных, которые остаются ограничены небольшим сообществом. Предоставляя наш набор данных открыто, мы, тем не менее, не рекомендуем использовать его для создания готовых к использованию промышленных продуктов, так как базовые исследования общих свойств и безопасности таких крупномасштабных моделей, которые мы хотели бы поощрять этим выпуском, все еще в ходе выполнения.
Погодите-ка, но сами создатели получается не рекомендуют свою же модель для коммерческих продуктов (которыми являются все нейросети). Этот момент как-то незаметно потерялся в восторгах на тему искусственного интеллекта.
К слову, по словам Мостака, гендиректора Stability AI частью которой является Stable Diffusion, на сегодняшний день обучение Stable Diffusion обошлось в 600 000 долларов (и это еще сэкономили, оценки затрат на обучение для других ISM обычно исчисляются миллионами долларов). В основном это затраты на банк из сотен высокопроизводительных графических процессоров, таких как Nvidia A100.
We actually used 256 A100s for this per the model card, 150k hours in total so at market price $600k
- Эмад Мостак
Несомненно эти деньги надо как минимум вернуть, а как максимум приумножить. И даже то, что подается бесплатным, по факту им не является.
К сожалению полный набор LAION-5B данных слишком громадный, поэтому доступ дают только к части, но этого вполне достаточно для изучения.
Переходим по ссылке https://rom1504.github.io/clip-retrieval/
Сверху строка поиска, слева галочки с настройками фильтров. Попробуем забить в поиск что-то, связанное с художественными работами, например “watercolor” - как видите куча работ из запрещенной нынче сети и даже Марковка дважды в топе выдачи.
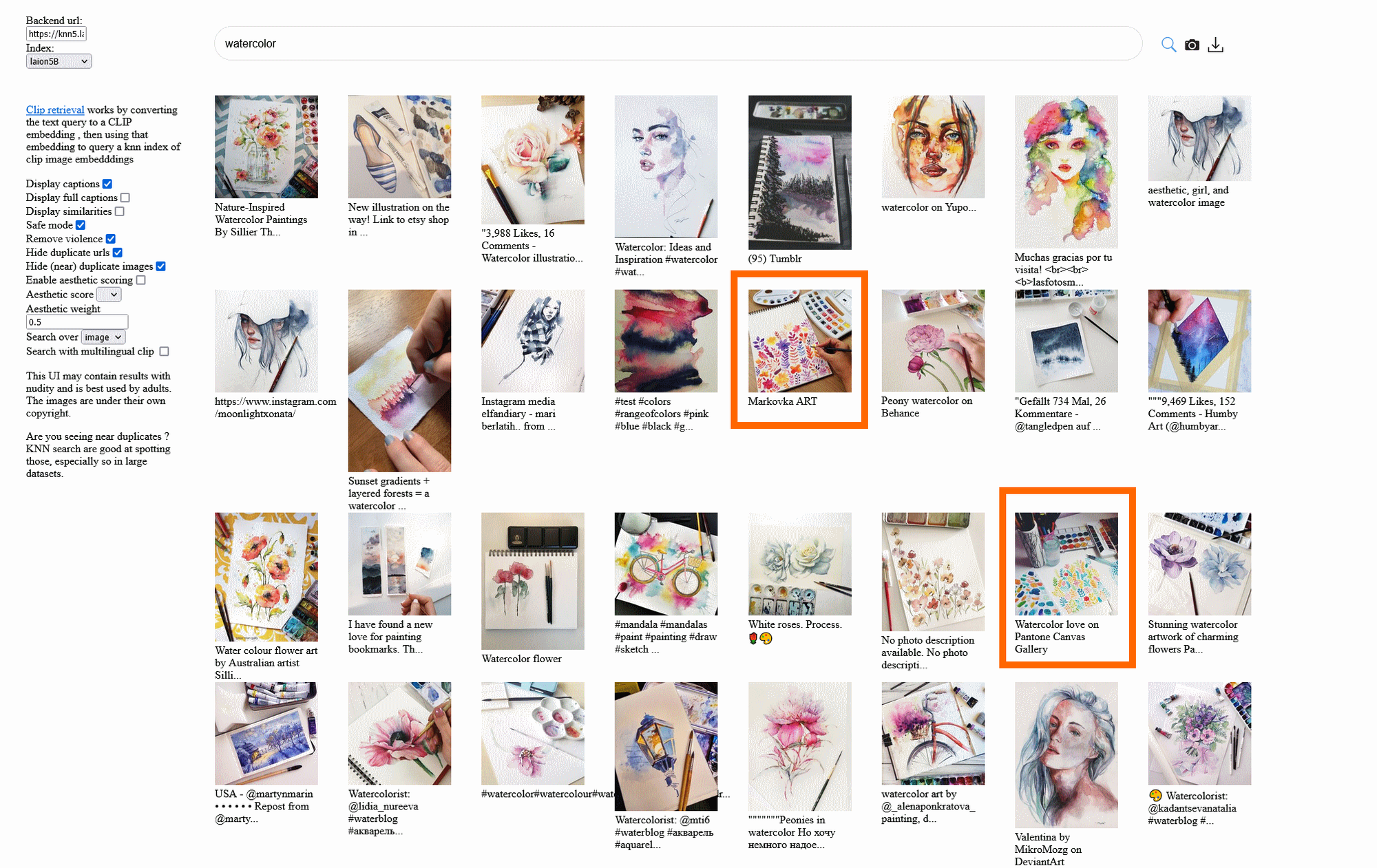
Можно повбивать что-то вроде “shutterstock vector” и тоже поискать свои работы. А самое главное, что картинки из этой базы можно скачать, несмотря на то, что датасет их не хранит - слева от поисковой строки иконка со стрелкой вниз скачивает JSON по вашему запросу и там список ссылок, по которым лежат картинки. Переходите и получаете картинку, готовую для скачивания.
Есть еще более интересный кусок на 12 миллионов пар картинка-текст: https://laion-aesthetic.datasette.io/laion-aesthetic-6pls/images?_sort_desc=aesthetic Вот тут можно поискать уже более художественные работы с того же artstation. Интересно еще, что здесь картинкам присвоен некий индекс эстетичности, непонятно как и кем высчитываемый.
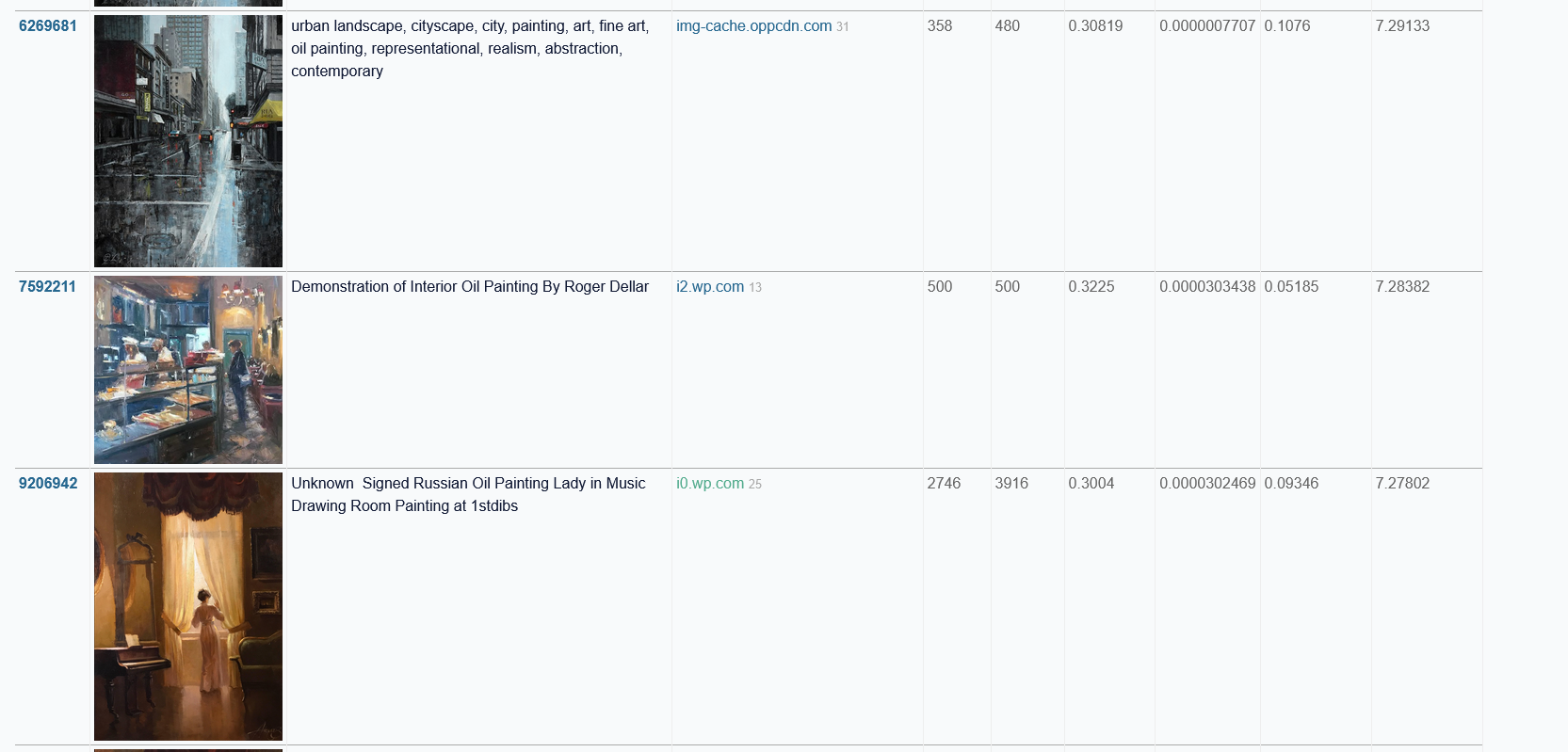
Создатели этой базы пишут, что проанализировали откуда картинки.
Мы проиндексировали 12 миллионов изображений в нашей выборке по доменам, чтобы выяснить это.
Почти половина изображений, около 47%, были получены только из 100 доменов, при этом наибольшее количество изображений поступило из Pinterest. Более миллиона изображений, или 8,5% от общего набора данных, взяты из CDN Pinterest на pinimg.com.
Платформы пользовательского контента были огромным источником данных изображений. Размещенные на WordPress блоги на wp.com и wordpress.com содержат 819 000 изображений вместе, или 6,8% всех изображений. Другие сайты с фотографиями, искусством и блогами включали 232 тыс. изображений с Smugmug, 146 тыс. изображений с Blogspot, 121 тыс. изображений с Flickr, 67 тыс. изображений с DeviantArt, 74 тыс. изображений с Wikimedia, 48 тыс. изображений с 500px и 28 тыс. изображений с Tumblr.
Торговые площадки тоже хорошо представлены. Вторым по величине доменом был Fine Art America, который продает художественные репродукции и плакаты, с 698 тыс. изображений (5,8%) в наборе данных. 244 000 изображений поступило от Shopify, по 189 000 от Wix и Squarespace, 90 000 от Redbubble и чуть более 47 000 от Etsy.
Неудивительно, что большое количество изображений пришло с сайтов стоковых изображений. 123RF был самым большим: 497 тыс., 171 тыс. изображений поступило из CDN Adobe Stock на ftcdn.net, 117 тыс. из PhotoShelter, 35 тыс. изображений из Dreamstime, 23 тыс. из iStockPhoto, 22 тыс. из Depositphotos, 22 тыс. из Unsplash, 15 тыс. из Getty Images, 10 тыс. из VectorStock и 10k от Shutterstock, среди многих других.
Однако стоит отметить, что сами по себе домены могут не представлять фактические источники этих изображений. Например, с домена Artstation.com получено всего 6 292 изображения, но еще 2 740 изображений со словом «artstation» в заголовке размещены на таких сайтах, как Pinterest.
Таким образом самой огромной дырой слива данных для нейросеток оказался Пинтерест, который сливает все что только можно, откуда можно. Ну и стоки, так горячо любимые, тоже не отстают.
Печально так же то, что удаление ваших данных из набора данных LAION ничего не дает, потому что это действие не удалит их ни из одной из моделей, которые уже были обучены помощью датасета. Попробовать запросить удаление можно по этой ссылке, но бесполезно пытаться быть быстрее роботов, которые парсят все на лету, пока вы удаляете одно, другое уползает в сеть. Чтобы удалить что-то, еще придется попотеть и найти все данные, типа ID картинки.
Чтобы прекратить это воровство, должна быть опция явного запрета использования своих работ для нейросетей, которая пока не появилась.
Вот такие “открытые данные” лежат в основе нейросетей. Если у вас еще были сомнения касательно берут ли картинки с творческих сайтов - да, берут. Абсолютно точно все это есть в Stable Diffusion, остальные просто не раскрывают на чем учили, но вариантов немного. Парадоксальная ситуация, если задуматься - художники выкладывают иллюстрации в интернет, чтобы найти работу и показать свое мастерство, а в итоге приходит самый находчивый и оборачивает все против арт индустрии, чтобы состричь бабла естественно на “открытом” контенте.
Если вам интересны посты про нейросети - подписывайтесь на теги ниже.
#нейросеть #нейросети #dalle2 #midjourney #stable_diffusion #карьера #рисование #рынок_труда #лицензия #авторам #художникам #восстание_машин #жизнь_без_людей #датасет #laion5b #открытые_данные




